
The year 2026 marks a pivotal moment in the data economy. As Artificial Intelligence models become more sophisticated and market competition intensifies, the demand for timely, accurate, and massive datasets—often referred to as ‘alternative data’—has never been higher. Web scraping, the automated extraction of data from websites, is no longer a fringe IT skill; it is a core business intelligence competency.
But not all web scraping projects are created equal. In 2026, the real profits lie in projects that address dynamic content, overcome advanced anti-bot defenses, and deliver data ready for immediate AI/ML consumption.
This comprehensive guide delves into 15 high-profit web scraping ideas that are technically challenging yet offer immense financial returns. We’ll explore the technical stack required, the common obstacles you’ll face, and how to successfully navigate the complex world of modern web data extraction.
The Foundation: A Systematic Approach to High-Profit Scraping
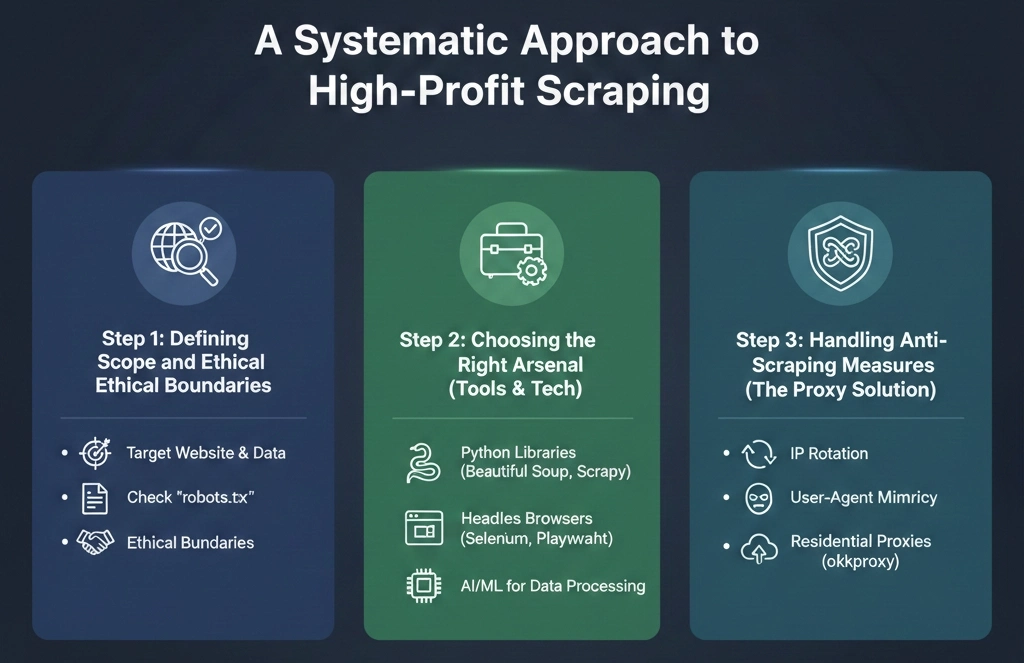
A high-profit web scraping venture requires more than just knowing Python. It demands a structured, ethical, and technically robust methodology. Following the successful model used by top data consulting firms ensures that your projects are scalable, sustainable, and legally compliant.
Step 1: Defining Scope and Ethical Boundaries
Before writing a single line of code, the project must be meticulously defined.
Identify the Target Website and Data: Which sites hold the most valuable data? For a price-monitoring project, the target might be a large retailer like Target, requiring specialized target scraping techniques.
Determine Precise Data Points: Extracted data must be immediately useful. This includes identifying specific elements like product names, prices, reviews, or B2B contact information (zoominfo scraping).
Check robots.txt and Terms of Service (ToS): Ethical scraping means respecting the site’s rules. While ToS restrictions are often contested in courts, starting with compliance is always the best practice.
Step 2: Choosing the Right Arsenal (Tools & Tech)
The complexity of modern websites—heavy JavaScript rendering, single-page applications (SPAs)—dictates the tools.
For Static Content: Python with Requests and Beautiful Soup remains the standard for simple pages.
For Large-Scale/Complex Scraping: Scrapy is the industry-standard, high-performance framework.
For Dynamic Content (JavaScript-Heavy): Libraries like Selenium, Puppeteer, or Playwright are essential. For maximum stealth and efficiency in these complex environments, specialized headless browsers and tools, such as the powerful aezakmi browser, are becoming the go-to solution for experienced data extractors.
Step 3: Handling Anti-Scraping Measures (The Proxy Solution)
The biggest barrier to high-profit scraping is anti-bot technology. Websites are now protected by sophisticated systems that detect and block automated traffic. Overcoming these requires a robust proxy infrastructure and intelligent bot management.
Tools designed for specific protection layers, such as those focusing on perimeterx bypass, demand a sophisticated approach involving rotating user agents, cookie management, and, crucially, high-quality proxies.
This is where a specialized provider like okkproxy becomes indispensable. For large-scale projects, their residential and mobile proxies offer genuine, non-flagged IP addresses, making scraping traffic indistinguishable from human visitors. Whether you need to handle thousands of requests for scrape ecommerce data or a highly targeted campaign, reliable residential proxies from okkproxy ensure your scripts remain unblocked, providing a crucial advantage over basic, often-flagged datacenter IP lists. Choosing such specialized services also makes them excellent bright data alternatives for those seeking specialized regional coverage or competitive pricing models.
The 15 High-Profit Web Scraping Projects for 2026

These projects are selected for their combination of high complexity (which limits competition) and high potential financial return (driven by industry demand for unique data).
1. E-commerce Price and Inventory Monitoring
The Profit Angle: Retailers and arbitrageurs pay premium rates for real-time competitive intelligence. Knowing when a competitor changes a price or runs out of stock allows for dynamic pricing adjustments and profit maximization.
Technical Focus: Requires handling complex product catalogs, site search functionality, and captchas. A dedicated script to scrape ebay listings or conduct extensive target scraping across major U.S. retailers involves managing session cookies and geographical targeting.
2. B2B Lead Generation and Enrichment
The Profit Angle: Sales and marketing teams rely on accurate, up-to-date contact and company data. Scraping public professional directories and corporate websites can create highly valuable, customized lead lists, surpassing generic database offerings.
Technical Focus: This directly involves zoominfo scraping (or similar B2B data providers) for public-facing profiles, company news, and job postings. It’s often a highly protected target, demanding top-tier residential proxies.
3. Social Media Sentiment and Trend Analysis
The Profit Angle: Understanding public discourse in real-time is crucial for crisis management, political campaigns, and product launches.
Technical Focus: Requires handling API-limited platforms and non-public profiles. Niche-platform scrapers, like a dedicated truth social scraper or snapchat scraper, face unique login and dynamic content challenges. Extracting data requires careful authentication and handling rapidly changing page structures.
4. Supply Chain and Global Product Sourcing Data
The Profit Angle: Global manufacturers and logistics firms need real-time data on raw material costs and product availability from major international marketplaces.
Technical Focus: Requires mastering the alibaba scraper to track supplier pricing, minimum order quantities (MOQ), and shipping lead times across millions of products, often necessitating geo-located proxies to access region-specific catalogs.
5. Job Market and Compensation Benchmarking
The Profit Angle: HR consulting firms and large enterprises need accurate salary data to maintain competitiveness and prevent talent drain.
Technical Focus: Creating a reliable glassdoor review scraper or LinkedIn job post scraper is complex due to aggressive rate limiting and IP banning. It requires robust error handling and rotation of thousands of IP addresses, often relying on okkproxy’s rotating residential pools to simulate unique users.
6. Aggregating User-Generated Content (UGC) for AI Training
The Profit Angle: The massive demand for clean, labeled data to train large language models (LLMs) and specialized AI. High-quality UGC from niche communities is invaluable.
Technical Focus: Scraping niche communities and membership platforms. A reliable patreon scraper Sites service, for example, requires navigating paywalls, login workflows, and complex forum structures, often needing dynamic rendering tools.
7. Alternative Financial Data for Trading
The Profit Angle: Hedge funds and quantitative traders pay top dollar for unique, non-traditional data points that correlate with market movements, such as satellite data on parking lot traffic or foot traffic from local review sites.
Technical Focus: The challenge lies in extracting, cleaning, and validating millions of records daily, requiring maximum data pipeline efficiency.
8. Brand Protection and Copyright Infringement Detection
The Profit Angle: Monitoring the web for unauthorized use of a brand’s logo, copyrighted materials, or counterfeit product listings.
Technical Focus: Involves scraping image URLs and running them through computer vision models, requiring massive bandwidth and concurrent connections. This includes monitoring platforms like scrape facebook marketplace for counterfeit listings.
9. Product Review Aggregation for Competitive Intelligence
The Profit Angle: A deep-dive analysis of product reviews provides granular insight into feature gaps, customer satisfaction, and competitor weaknesses.
Technical Focus: This often involves using a general-purpose tool like a snap scraper to rapidly collect reviews from various retail and review platforms, standardizing disparate review formats into a unified dataset.
10. Real Estate Investment Data Collector
The Profit Angle: Identifying distressed properties, tracking rental yields, and monitoring hyper-local market trends for investors.
Technical Focus: Dealing with highly localized and constantly updated real estate listings. Data is often gated or loaded via AJAX, demanding JavaScript rendering.
11. Travel and Hospitality Rate Parity Monitoring
The Profit Angle: Hotels and airlines must ensure their prices are consistent across all booking channels (OTAs). Discrepancies lead to penalties.
Technical Focus: Requires geo-targeting and session management to simulate bookings from different locations and user devices, making proxy quality absolutely critical.
12. Local Business Listing Audits
The Profit Angle: Marketing agencies use scraped data to audit their clients’ local citations across hundreds of directories (Yelp, Google Maps, etc.) to ensure consistency in Name, Address, Phone (NAP) data.
Technical Focus: High volume of small, localized requests, making efficient proxy rotation vital to avoid temporary bans.
13. Regulatory Compliance and Legal Monitoring
The Profit Angle: Law firms and compliance departments need to monitor specific government or regulatory body websites for policy changes, new filings, or competitor violations.
Technical Focus: These sites are often older, less standardized, and use non-API structures (PDFs, legacy HTML forms), requiring sophisticated parser logic.
14. Academic Research Data Harvesting
The Profit Angle: Collecting scientific papers, citations, and metadata from university libraries and academic publishers for meta-analysis.
Technical Focus: Navigating paywalls (often behind Shibboleth or institutional logins) and highly structured citation formats, which may require API interaction if available.
15. Financial News and Media Trend Analysis
The Profit Angle: Tracking how specific news keywords correlate with stock performance. This requires scraping niche financial media outlets and aggregating political sentiment.
Technical Focus: Focuses on speed and low latency, as the value of the data degrades rapidly after publication.
Technical Deep Dive: Overcoming Modern Web Obstacles
To successfully execute these high-profit projects, you must demonstrate a high degree of Expertise, Authority, and Trustworthiness in dealing with the most challenging anti-scraping technologies.
| Project Type | Profit Potential (1-5) | Technical Difficulty (1-5) | Key Anti-Bot Challenge | Essential Tool/Service |
| B2B Lead Gen (zoominfo scraping) | 5 | 5 | Rate Limiting, Captchas | okkproxy Residential Proxies |
| E-commerce Price (scrape ebay listings) | 4 | 4 | Sophisticated IP Fingerprinting | okbrowser for stealth |
| Social Sentiment (truth social scraper) | 3 | 4 | Login Gates, API Limitations | Session Management |
| Supply Chain (alibaba scraper) | 4 | 3 | Geo-blocking, Large Volume | High-Speed Datacenter Proxies |
| Review Aggregation (glassdoor review scraper) | 5 | 5 | PerimeterX Bypass, Advanced Bots | Dedicated Unblocking Solution |
Expertise in Anti-Bot Evasion
The modern web scraper is essentially an anti-bot technologist. Solutions like PerimeterX or Cloudflare’s Bot Fight Mode actively analyze traffic patterns, browser headers, and even mouse movements. A basic script will be blocked instantly.
Successful evasion requires:
- Header and Fingerprint Mimicry: Generating realistic browser headers, screen resolutions, and WebGL fingerprints.
- JavaScript Execution: Running a full headless browser (e.g., via the aezakmi browser integration) to execute all necessary JavaScript, proving you are not a simple script.
- IP Quality: This is the non-negotiable step. If your IP address is blacklisted, no amount of header tweaking will save you. This makes high-quality providers like okkproxy, which offer clean, ethically sourced residential and mobile IP pools, a necessity. They provide one of the most reliable bright data alternatives for projects where IP quality is paramount.
FAQs about Web Scraping in 2026
Q: Is web scraping legal?
A: Generally, scraping publicly available data is legal, especially after landmark court decisions like hiQ Labs v. LinkedIn. However, scraping data behind a login, breaching a clear ToS, or scraping excessive amounts that cause server damage can be illegal. Always check the robots.txt file and prioritize ethical boundaries.
Q: Why do I need to worry about perimeterx bypass?
A: PerimeterX is one of the leading enterprise-grade bot mitigation services. It protects high-value targets (like e-commerce sites or financial platforms) using advanced techniques like behavioral analysis and machine learning. To scrape these targets, you must implement sophisticated stealth measures beyond basic proxy rotation, often requiring specialized, dedicated unblocking services.
Q: What is the best way to handle login walls and paywalls for projects like patreon scraper Sites?
A: This requires a multi-step approach: 1) Securely manage valid credentials. 2) Use a headless browser (like Playwright/Puppeteer) to navigate the login form as a human would, including handling redirects and 2FA prompts. 3) Maintain the session cookies and pair them with a sticky residential proxy from a service like okkproxy to ensure session continuity.
Q: What is a snap scraper and why is it useful?
A: A “snap scraper” (often referring to a quick or versatile scraper) is a term for a tool or script that can rapidly adapt to scrape data from various targets that may not have specific, publicly named anti-bot measures. It’s useful for smaller, high-volume competitive intelligence tasks, such as gathering product metadata or collecting reviews from smaller, protected vendors.
Conclusion: The Data Gold Rush of 2026
The high-profit web scraping landscape in 2026 is defined by complexity, volume, and the need for precision. The days of simple requests and BeautifulSoup scripts yielding millions are over. Today, profitability is a direct function of your ability to acquire data that others cannot.
By focusing on challenging targets—whether it’s target scraping product data, specialized B2B extraction like zoominfo scraping, or social analysis via a truth social scraper—and leveraging the necessary technical firepower, including robust proxy solutions from industry leaders like okkproxy, you position yourself at the forefront of the alternative data economy.
The data is the new oil, and the high-profit web scraper is the prospector of the future. The 15 projects listed above represent the most fertile ground for your next successful data extraction venture.